A Programming Model for Hybrid Workflows: combining Task-based Workflows and Dataflows all-in-one
Abstract
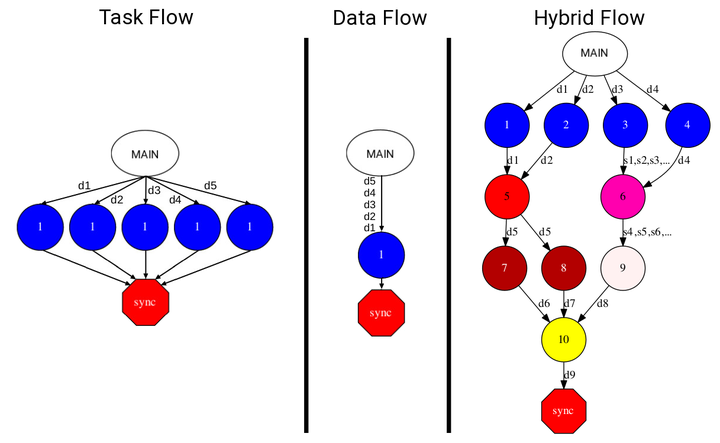
In the past years, e-Science applications have evolved from large-scale simulations executed in a single cluster to more complex workflows where these simulations are combined with Artificial Intelligence (AI) and High-Performance Data Analytics (HPDA). To implement these workflows, developers are currently using different patterns; mainly targeting task-based and dataflow. However, since these patterns are usually managed by isolated frameworks, the implementation of these applications requires to combine them; considerably increasing the effort for learning, deploying, and integrating applications in the different frameworks. This paper tries to reduce this effort by proposing a way to extend task-based management systems to support continuous input and output data to enable the combination of task-based workflows and dataflows (Hybrid Workflows from now on) using a single programming model. Hence, developers can build complex Data Science workflows with different approaches depending on the step requirements. To illustrate the capabilities of Hybrid Workflows, we have built a Distributed Stream Library and a fully functional prototype extending COMPSs, a mature, general-purpose, task-based, parallel programming model. The library can be easily integrated with existing task-based frameworks to provide support for dataflows. Also, it provides a homogeneous, generic, and simple representation of object and file streams in both Python and Java; enabling complex workflows to handle any data without dealing directly with the streaming back-end. During the evaluation, we introduce four use cases to illustrate the new capabilities of Hybrid Workflows, and measure the performance benefits when processing data continuously as it is generated, when removing synchronisation points, and when scaling the number of writers and readers. Furthermore, we conduct an in-depth analysis of the task analysis, task scheduling, and task execution times when using objects or streams.
Keywords
Cristián Ramón-Cortés Vilarrodona
PhD
Dr. Cristián Ramón-Cortés Vilarrodona works as a Team Lead at Dynatrace.